
L’edge computing est l’étape suivante dans l’évolution du cloud computing. Le traitement et le stockage des données sont déportés à la périphérie du réseau et non plus vers des serveurs distants. Les données sont ainsi traitées en local et ne transitent pas nécessairement par le cloud. La data reste au plus proche des hommes ou des machines qui la produise ou l’exploite.
#1 Qu’est-ce que l’Edge Computing
Une nouvelle forme d’architecture pour les environnements IoT
L’edge computing est une architecture destinée aux environnements IoT où les données sont traitées en local et en périphérie du réseau, et non dans le Cloud ; « edge » vient d’ailleurs de l’anglais et signifie bord ou périphérie. Représentant une alternative aux solutions de cloud avec des serveurs centralisés, l’edge computing permet de maintenir les ressources informatiques, la capacité de stockage et la puissance de calcul au plus près des terminaux et des objets connectés qui génèrent de la data. Le principal avantage à cette architecture est le délai (en temps réel) de traitement des données de masse générées par des usines, des réseaux de distributions ou des systèmes de circulation « intelligents », et de prendre immédiatement les mesures nécessaires en cas d’incidents.
Pour bien comprendre l’edge computing…
Voici un aperçu des éléments fondamentaux :
- Edge : dans le jargon informatique, le mot « edge » désigne la périphérie du réseau. Quant à savoir quels seront les éléments implantés en périphérie du réseau, cela dépendra de la configuration mise en place. Dans des réseaux de télécommunication, ce sera par exemple un téléphone portable qui représentera la périphérie du réseau ; et dans un système de voitures autonomes interconnectées, chaque véhicule. On parle dans ce cas d’un edge device.
- Edge device : on entend par edge device tout appareil situé en périphérie de réseau, et qui génère des données. Les sources de données possibles sont par exemple des capteurs, des machines, des véhicules ou tous les autres appareils intelligents dans un environnement IoT, comme des lave-linge, des détecteurs d’incendie, des ampoules ou des thermostats pour radiateur.
- La passerelle Edge : la passerelle Edge est une instance de calcul implantée à la transition entre deux réseaux. Dans des environnements IoT, les passerelles Edge sont utilisées comme nœuds entre l’Internet des objets et le réseau central. On a aussi de puissants routeurs, capables de supporter de fortes puissances de calcul pour assurer le traitement des données de l’IoT. Pour ce faire, les passerelles Edge disposent de diverses interfaces permettant de transférer les données soit par câble, soit par radio, et de standards de communication, comme l’Ethernet, le Wifi, le Bluetooth, la téléphonie 3G, LTE, Zigbee, Z-Wave, CAN-Bus, Modbus, BACnet ou SCADA.
Ce que permet l’edge computing
- Une optimisation de la bande passante pour l’analyse des grands volumes de données, comme le flux vidéo d’une caméra de surveillance ;
- Une réduction du délai de latence pour les services nécessitant un traitement en temps réel, comme la voiture autonome ;
- Un surplus d’autonomie aux objets connectés grâce à une gestion frugale de leurs ressources ;
- La poursuite de l’activité en local en dépit d’éventuels problèmes de connexion au cloud central ;
- L’exécution en local de services cognitifs gourmands en ressources de calcul, comme la reconnaissance faciale ;
- Un renforcement de la sécurisation des données sensibles (notamment dans la santé, l’industrie) ;
- Le respect des exigences règlementaires grâce au traitement, au stockage et à la suppression des données personnelles au plus près de la source.
Un objectif de qualité de service
La viabilité du modèle edge computing reste encore à prouver. En effet, le succès ou l’échec des centres de données du edge computing est conditionné par la capacité à atteindre les objectifs de niveau de service (SLO – service level objective). Ce sont les attentes des clients qui paient pour les services, telles qu’elles sont codifiées dans leurs contrats de service. Les ingénieurs disposent de mesures qu’ils utilisent pour enregistrer et analyser les performances des composants du réseau.
Dans le cadre d’un contrat type de fournisseur de centre de données, un SLO est souvent mesuré à la rapidité avec laquelle le personnel du fournisseur peut résoudre un problème en suspens. En général, les délais de résolution peuvent rester faibles lorsque le personnel n’a pas à se déplacer par la route. Si un modèle de déploiement de edge computing doit être compétitif par rapport à un modèle de déploiement en colocation, ses capacités de résolution automatisée ont intérêt à être très bonnes.
#2 L’edge Computing et fog computing : même combat ?
Se substituant au concept plus ancien de fog computing, ce traitement à la “périphérie” du cloud a pour but d’absorber la demande liée à la croissance fulgurante annoncée de l’Internet des objets (IoT). Pourtant cette approche visant à étendre le Cloud autour des instances de calcul n’est pas nouvelle. En 2014 déjà, le groupe américain Cisco a créé le terme marketing, baptisé « fog computing». Ce concept est basé sur un traitement décentralisé des données dans ce qu’on appelle des « nœuds fogs ». Les nœuds fog représentent de mini-centres de calcul positionnés en amont du Cloud, constituant une couche intermédiaire dans le réseau (on parle de « couche fog »). Les données générées dans des environnements IoT ne sont donc pas directement envoyées dans le Cloud. Elles sont d’abord collectées dans des Fog Notes, où elles sont interprétées avant d’être sélectionnées pour d’autres formes de traitement.
L’edge computing est aujourd’hui considéré comme faisant partie du fog computing, où les ressources informatiques, comme la puissance de calcul et la capacité de stockage sont rapprochées au mieux des équipements IoT, en périphérie du réseau. Dans des architectures de fog computing, le traitement des données se fait d’abord au niveau de la couche fog, tandis que dans des concepts d’edge computing, il est exécuté au niveau de puissants routeurs IoT, et même parfois directement sur les appareils ou sur les capteurs. On peut parfaitement envisager une combinaison des deux concepts. Parce qu’une image est parfois plus parlante que des mots, voici un schéma montrant une telle architecture avec une couche Cloud, fog et edge.
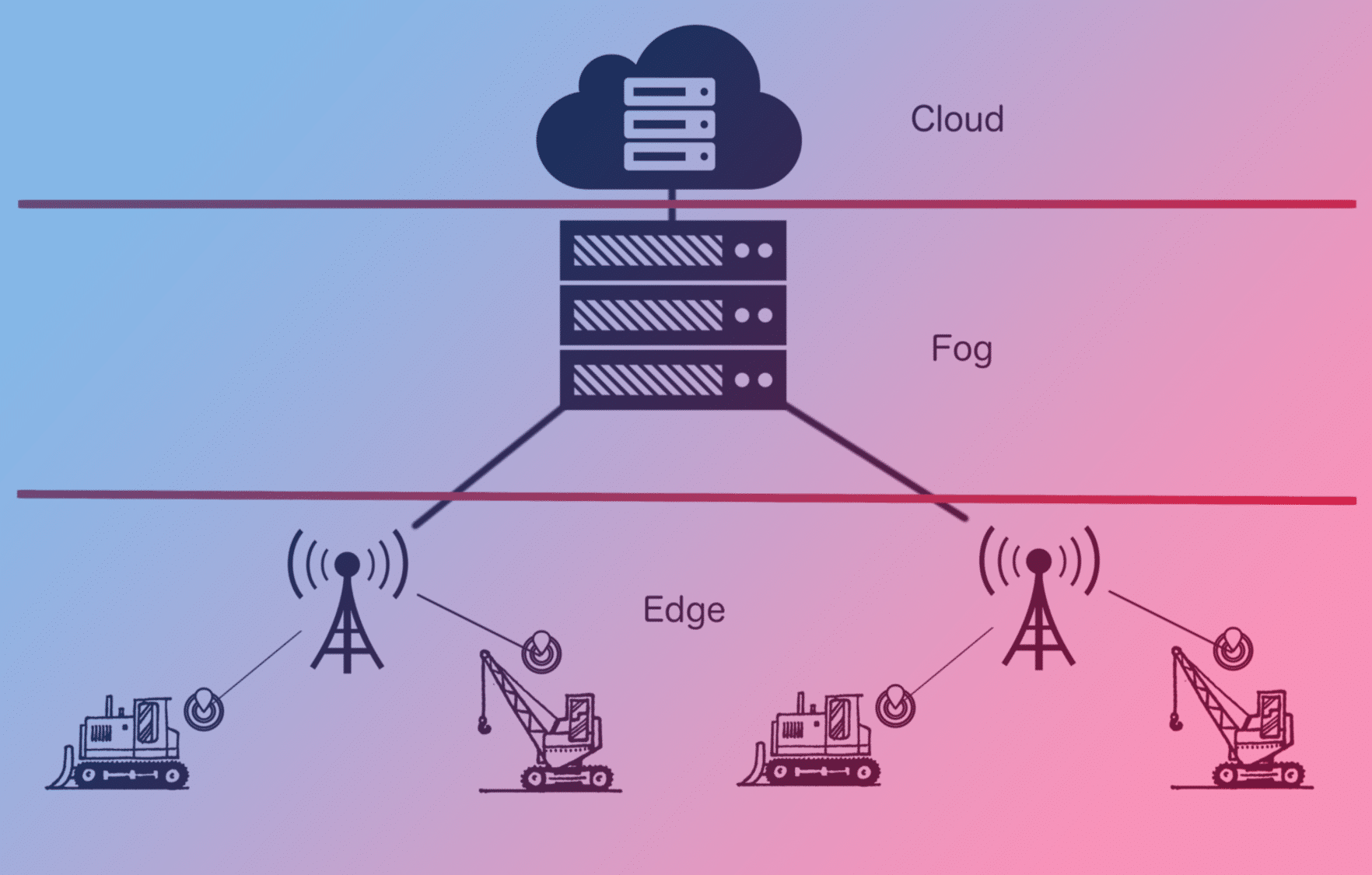
#3 Pourquoi l’Edge Computing a un potentiel aussi important ?
Un complément au cloud
Aujourd’hui, ce sont les grands centres de données qui supportent l’essentiel du volume des données générées par Internet. Les sources de données sont pourtant très souvent mobiles de nos jours, et trop éloignées des gros ordinateurs centraux pour pouvoir garantir un délai de latence satisfaisant. Ce facteur pose problème, en particulier pour les applications critiques comme l’apprentissage automatique et la maintenance prévisionnelle, deux concepts de base dans le domaine de l’Industrie 4.0 avec des sites de production intelligents et des réseaux de distribution auto-régulés par exemple.
Avec une vitesse de transfert pouvant atteindre les 10 Go/s, la mise en œuvre du nouveau réseau mobile 5G ne devrait pas régler le problème du volume croissant des données, mais plutôt l’accentuer, à en croire les experts en la matière. L’edge computing n’est pas non plus la solution à ce problème. Le concept pose cependant bien la question de savoir si toutes les données d’un environnement IoT doivent bel et bien être traitées dans le Cloud.
L’edge computing ne vient donc pas remplacer le Cloud, mais il le complète avec les fonctionnalités suivantes :
- Saisie et agrégation des données : alors que les sources de données des architectures Cloud classiques acheminent toutes leurs données vers un ordinateur central du Cloud pour y être traitées, l’edge computing mise sur un enregistrement des données au plus près de la source. On utilise pour ce faire des micro-contrôleurs, directement installés sur l’appareil. On les appelle aussi des passerelles Edge, c’est à dire des routeurs intelligents. Ils ont pour fonction de collecter les données provenant de différents appareils, et permettent un pré-traitement et une sélection du jeu de données. Le téléchargement des données vers le Cloud ne se fait alors que si les informations ne peuvent pas être traitées en mode local, si des analyses plus poussées doivent être effectuées ou s’il y a un besoin d’archiver certaines informations.
- Saisie des données en mode local : l’edge computing s’impose avant tout lorsque les données générées sur le plan local nécessitent la présence d’une très large bande passante. En cas de gros volume de données, il n’est généralement pas possible de procéder à un transfert en temps réel de l’ordinateur central vers le Cloud. On évite ce problème si on opte pour un traitement décentralisé de ces données en périphérie du réseau. Dans un tel scénario, les passerelles Edge font office de serveurs de réplication dans un réseau de diffusion de contenu.
- Monitoring piloté par intelligence artificielle : les unités de calcul décentralisées d’un environnement edge computing accueillent les données, les interprètent, et permettent de cette manière d’assurer un suivi continu des appareils connectés. Avec des algorithmes du Machine Learning, il est possible de réaliser en temps réel un contrôle des statuts, par exemple pour contrôler et optimiser les processus de fabrication dans des usines intelligentes.
- La communication M2M : l’abréviation « M2M » désigne l’expression « Machine-to-Machine », une manière de décrire la communication automatique entre des machines en s’appuyant sur toutes sortes de standards pour la communication. On pourrait par exemple recourir à la communication M2M pour surveiller à distance des machines et des sites de production dans un environnement IoT, comme une usine intelligente. Dans le cadre du suivi des procédés, il est à la fois possible d’assurer une communication entre les équipements terminaux, mais également une communication avec une centrale, qui fonctionnera comme instance de contrôle (monitoring piloté par intelligence artificielle).
Des domaines d’application sur des projets d’avenir
L’un des facteurs important de croissance de la technologie de l’edge computing est le besoin croissant de systèmes de communication fonctionnant en temps réel. Le traitement décentralisé des données est une technologie clé pour les projets suivants :
- La communication de véhicule à véhicule
Le futur de la mobilité permettra la mise en place de systèmes d’avertissement gérés par le Cloud, permettant une communication de véhicule à véhicule, voire des moyens de transport complètement autonomes dans leurs déplacements. La condition est cependant que l’on puisse disposer d’une infrastructure permettant d’échanger en temps réel des données entre les véhicules et les différents points de communication tout au long de l’itinéraire. - Le réseau électrique intelligent
Le réseau électrique tel que les experts l’imaginent, sera lui aussi adaptatif, capable de s’auto-réguler automatiquement en fonction des besoins grâce à des systèmes de gestion d’énergie décentralisés. Dans le cadre de la transition énergétique, le réseau électrique intelligent pourrait représenter une technologie clé. En effet, la conversion vers des énergies renouvelables impose de nouveaux défis aux réseaux d’électricité. Au lieu d’avoir quelques gros producteurs centralisés, on aura de nombreux petits producteurs d’énergie décentralisés, avec des dispositifs de stockage qui devront être connectés avec les consommateurs. Certains d’entre eux sont eux-mêmes producteurs d’énergie, notamment grâce aux panneaux solaires. - Le Smart Factory
Dans l’usine de futur idéale, il n’y aucune intervention humaine. Une usine intelligente est un système interconnecté d’appareils, de machines et de capteurs qui communiquent entre eux par Internet pour mener à terme des processus de fabrication. Le système de communication Smart Factory inclut le produit fini dans son système et peut donc réagir automatiquement face à des demandes de devis. Grâce à des systèmes d’intelligence artificielle et à un apprentissage autonome, on a des processus de maintenance qui optimisent la production. Ce type de concept est exigent, impliquant une infrastructure informatique capable de traiter sans délai de gros volumes de données, et de réagir rapidement à des imprévus. Les systèmes de Cloud traditionnels échouent pour des raisons de latence. Les architectures d’edge computing et de fog computing peuvent résoudre ce problème grâce à un traitement des données partagé.
Ce qu’il faut retenir :
Entre les montres connectées, les enceintes vocales ou les capteurs industriels, le nombre d’objets connectés dans le monde devrait osciller cette année, selon les études, entre 30 milliards (Gartner) et 80 milliards (IDATE). D’ailleurs sur ce sujet, nous vous invitons à consulter notre article dédié au domaine de l’IoT et les secteurs impactés.
Pour toutes les raisons évoquées plus haut, l’edge computing est indiscutablement le sujet du moment et présente plusieurs avantages. Pourtant cette architecture comporte certains inconvénients…
Avantages :
- Traitement des données en temps réel : dans les architectures d’edge computing, les unités de calcul sont rapprochées au mieux des sources de données, favorisant une communication en temps réel. On évite ainsi le problème récurrent de latence rencontré avec les solutions de Cloud plus classiques.
- Débit utile réduit : l’edge computing privilégie un traitement des données en local au niveau de passerelles Edge. Seules les données qui ne peuvent pas être traitées localement, ou qui doivent être mises en lignes, sont téléchargées dans le Cloud.
- La sécurité des données : avec une solution d’edge computing, la majeure partie des données reste dans le réseau local. Dans une telle configuration, les entreprises auront plus de facilité à se conformer aux exigences de conformité.
Inconvénients :
- Des structures de réseau plus complexes : un système de répartition est bien plus compliqué qu’une architecture Cloud centralisée. Un environnement edge computing est un ensemble hétérogène de plusieurs composants de réseau, venant en partie de divers fabricants, et qui communiquent les uns avec les autres grâce à un grand nombre d’interfaces.
- Les frais d’acquisition pour du matériel Edge : les architectures de Cloud se distinguent avant tout par le fait qu’il y a beaucoup moins d’équipement matériel à installer localement. On perd cet avantage si on opte pour des systèmes à répartition.
- Un niveau de maintenance plus élevé : un système décentralisé, composé de plusieurs nœuds de calcul, nécessite plus d’entretien et d’administration qu’un centre de données.

Pingback: Edge computing : comprendre cette technologie et ses enjeux - Infos Techno()